
Self attention mechanism
Self attention mechanism
Attention: Measure the importance of the input sequence.
When reading long articles, your focus naturally shifts from one word to another, depending on the context.
The mechanism mimic this behavior, allowing models to selectively concentrate on specific elements of the input data while ignoring others.
Bert's bull attention mechanism
Each color is an attentional head, or a set of weights that represent the intensity of attention.
Different attention heads focus on different things, and eventually they combine to produce results.
The more layers you have under the same attention head, the more you focus on context.
For example, when the number of layers is low, a word pays more attention to the words around it, but as the number of layers increases, it also pays more attention to things outside the sentence.
Visualization
In this example, header 5 always focus on the last token:

And header 12 always focus on the next token:

Each type of head has its own focus, and here are two simple examples.
For example, some headers add pronoun matching:

When the ninth head is on the eleventh floor, it allows her to focus on the word it refers to (cat).
However, it is not necessarily matched at higher levels, and the attention mechanism has overfitting problems on small data sets.
The Quartet: Q, K, V and Self attention
Note: The length of these three vectors is not necessarily equal to the length of the sentence, their length is determined by the hidden dimensions of the model.
Q(Query)
For each word in the input sequence, a query vector is calculated. These queries represent what you want to pay attention to within the sequence.
It determines how much focus each token should place on the other tokens in the sequence.
K(Key)
Keys help identify and locate important elements in the sequence. Key vectors are computed for each word.
It's used to determine how relevant each token is to the current token being processed (the query).
V(Value)
These vectors hold the content that we want to consider when determining the importance of words in the sequence.
Procedure
1. Calculate Quartet of each word.
Suppose you have a sentence: The quick brown fox.
Tokenize:
['The', 'quick', 'brown', 'fox']
Query Vector:
Where
Embedding:
How Embedding calculated?
Assume our embedding dimension d is 5 (for simplicity).
The embedding matrix E might look like this (initialized randomly):
The model learns embeddings in the context of a larger task, such as predicting the next word (language modeling) or classifying a sentence (sentiment analysis).
Refine the embeddings through backpropagation and optimization during the training of the NLP model.
Linear Transformations
Assume the weight matrices
For token "The":
Similarly, we calculate for the other tokens, their W matrix are same.
2. Attention Scores
With the quartet prepared, attention scores are computed for each pair of words in the sequence. The attention score between a query and a key quantifies their compatibility or relevance.
This score represents how much attention the i word pays to the j word.
3.Weighted Aggregation
Finally, the attention scores are used as weights to perform a weighted aggregation of the value vectors. This aggregation results in the self-attention output, representing an enhanced and contextually informed representation of the input sequence.
Final Output Matrix
Each
The vectors in each row of this matrix represent the contextual perception of the corresponding word.

Multi-Head Attention
Multi-head attention is actually using more than one set of QKV to generate attention information, and finally add up the output result, so that the model can capture various types of information.

Positional Encoding
One critical aspect of self-attention is that it doesn’t inherently capture the sequential order of elements in the input sequence, as it computes attention based on content alone. To address this limitation, with information about the positions of words in the sequence, enabling it to distinguish between words with the same content but different positions.
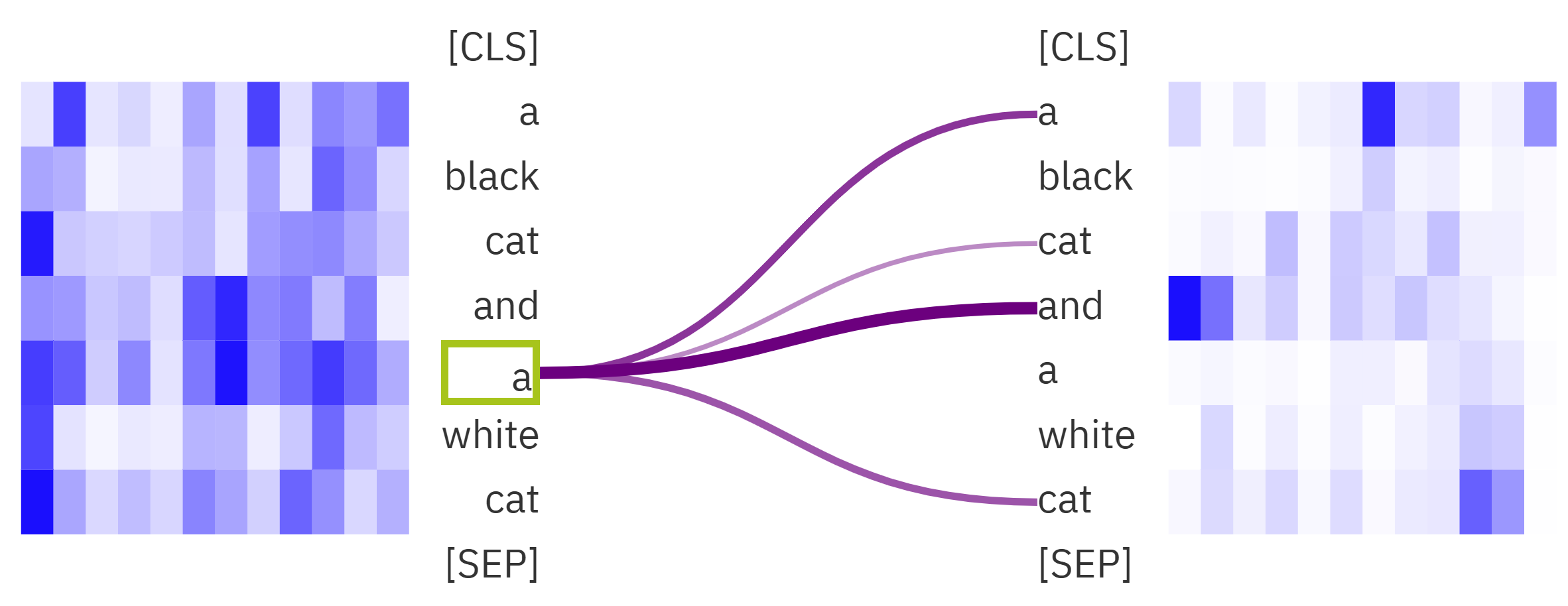
In this case, the latter "a" should obviously be more concerned with what it refers to, which is "white cat."