
Meta Learning
Meta Learning
這次學習並非清湯寡水,今天看理論,明天讀代碼,三位大廚正在全力烹飪。
concept
Meta-learning means "learn to learn", and while normal deep learning learns the function f, meta-learning learns how to get the function f.
| target | input | function | output | workflow | |
|---|---|---|---|---|---|
| Machine learning | Find the mapping f between x and y through the training data | x | f | y | 1.initialize f; 2.load data <x, y>; 3.calculate loss, optimize f; 4.find y=f(x) |
| Meta learning | Find a function f that generates the relation F by training the task and the data | Training tasks and their data | F | f | 1.initialize F; 2.load training tasks T and their data D, optimize F; 3.find f = F*; 4.in the new task: y = f(x) |
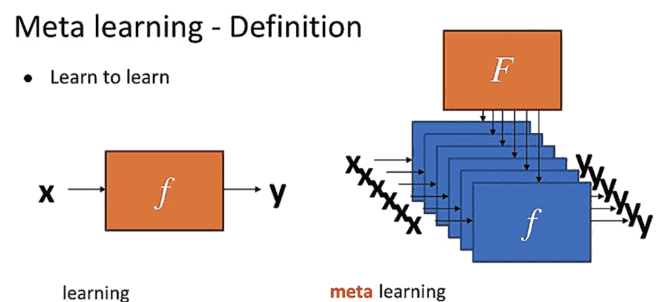
In machine learning, there is only one layer of training, which directly uses data as the training unit, but in meta-learning, the first layer of training unit is the task, and the second layer is the data (in fact, only a small amount of training is needed to the second layer, and the data obtained from the first layer can be directly processed to adapt to new tasks quickly, which is also known as fee-shot learning).
Bi-level optimization
Meta-training can be formalized as bi-level optimization:
Meta-testing for new task
Firstly, the meta-training set is divided into Support set and Query set. w can be viewed as an algorithm; θ can be considered as a model parameter.
In the Inner loop optimization stage, in the support set, the w algorithm is used to optimize θ parameters according to the performance of the loss value of the task. Finally, the optimal θ' value is obtained by the inner optimization according to the minimum
In the Outer loop optimization stage, in the query set, the current Lmeta value is calculated according to the optimal θ 'value of the inner layer optimization. After multiple tasks, the minimum total loss value of all tasks is calculated to optimize the w parameter, and the
The inner layer optimization deals with ordinary machine learning problems, and the outer layer takes the results of the inner layer as data to obtain the parameters of the metamodel, that is, the "hyperparameters" of ordinary machine learning problems.
Intensive reading of thesis
Source: https://arxiv.org/abs/1703.03400
MAML
Problem Set-Up
The goal of few-shot meta-learning is to train a model that can quickly adapt to a new task using only a few datapoints and training iterations.
consider a model, denoted
A generic notion of a learning task:
Each task
consists of a loss function
In supervised learning problems, the length
During meta-training, a task
MAML
The intuitive analysis of this algorithm is that there must be an internal pattern that is most transferrable, just find it.
Meta-learning is also based on gradient descent, so it is only necessary to find the parameters that are sensitive to task changes, and when they change, the task loss under the task set will be greatly affected.

When faced with a particular task, parameter
Consider a model represented by a parametrized function
We will update
Our task(meta-objective) now becomes to find a specific
Meta optimization is the optimization of
The meta-optimization across tasks is performed via SGD, the model parameters
where
| Pseudocode of MAML |
|---|
| randomly initialize while not done do sample batch of tasks for all evaluate compute adapted parameters with gradient descent: end for update end while |
Since the update of the metagradient goes through two loops (updating the outer gradient by the gradient of the inner layer), an additional reverse pass through
About Hessian-vector product
A Hessian matrix is a matrix consisting of the second partial derivatives of a function whose independent variables are vectors.
Consider a function:
If all the second partial derivatives of
where
For a set of parameters
In meta-learning, the outer layer optimization involves the results of the inner layer optimization, which leads to the gradient of the outer layer loss function not only dependent on the current model parameters, but also on how the model is optimized by updating the inner layer gradient. Therefore, the gradient calculation of the outer layer optimization usually contains second-order derivative information, so the Hessian matrix is required. However, computing the complete Hessian matrix faces a huge complexity of
Species of MAML(apply)
Supervised Regression and Classification
Few-shot learning makes it possible to use only a small amount of data to perform classification tasks, such as recognizing cats based on a large number of other types of objects that it have seen before.
Since the model accepts a single input and produces a single output, rather than a sequence of inputs and outputs, we can define the horizon
Two common loss functions used for supervised classification and regression are cross-entropy and mean-squared error(MSE):
where
For discrete classification tasks with a cross entropy loss:
K-shot classification tasks use
| Pseudocode of MAML for Few-Shot Supervised Learning |
|---|
| randomly initialize while not done do sample batch of tasks for all Sample Evaluate Compute adapted parameters with gradient descent: Sample datapoints end for Update end while |
Reinforcement Learning(MDP)
Reinforcement learning is a learning mechanism that learns how to map from state to behavior in order to maximize the reward obtained. Such an agent needs to continuously experiment in the environment and optimize the state-behavior correspondence through the feedback (reward) given by the environment.
Each RL task
Notice that instead of using the loss function directly, we've created an artificial loss function by first calculating the reward and then taking the negative sign.
The reward function is usually not differentiable, and the loss function is not differentiable. We use policy gradient method s to estimate the gradient both for the model gradient update(s) and the meta-optimization. In the strategy gradient algorithm, the input to the strategy function is the state ss and the action a aa, and the output is a probability value between 0 and 1. A later article will explain how the strategy gradient is implemented.
| Pseudocode of MAML for Reinforcement Learning |
|---|
| randomly initialize while not done do sample batch of tasks for all Sample Evaluate Compute adapted parameters with gradient descent: Sample trajectories end for Update end while |
This algorithm has the same structure as Algorithm 2, with the principal difference being that steps 5 and 8 require sampling trajectories from the environment corresponding to task $ \mathcal{T}_i$.
Experimental Evaluation
I will not explain this part in detail, but a set of graphs is given in the original paper, which can be seen that the model using MAML has understood the characteristics of sine waves:
