
RL: Overview and basic policy gradient
RL: Overview and basic policy gradient
Difference between normal supervised learning
Reinforcement learning is unsupervised and it will solve the problem there is no standard answer(or humans also don't know the best way to solve).
The basic problems and parameters
All the purpose of the machine learning problem is to find a function, reinforcement learning is no exception.
To find a function is a set of Actor:

In the learning process of chess, since there is no reward for moving in the chess game no matter how, it is stipulated that winning a game gets 1 point, losing a game gets -1 point.
Three components of reinforcement learning
Function with unknown
Policy Network(Actor), input from environment(observation of machine represented as a vector or matrix), output an action, actually it's a classification task, each action corresponds to a neuron in output layer.
In order to ensure randomness(paper scissor stone), the probability is usually determined according to the reward, and then the behavior is randomly selected according to the probability, rather than directly choosing the behavior with the highest reward.
Define loss
The entire process from the beginning of training to the triggering of the termination condition that brings the game to an end is called an episode.
A total reward(return) can be calculated at the end of an episode:
Our target is to maximize
Optimization
Find a set of network parameters that make the total reward as large as possible.

A complete set of s and A is called Trajectory:
Calculating the
Difficulty
Since action is generated by probability, the network may take different actions when faced with the same environment.
Also, the mechanics of environment and reward are not clear, and we can only treat them as black boxes. To make matters worse, the circumstances and rewards are also random in some cases(For example, in chess, the opponent's position is uncertain when facing the same game).
Policy Gradient
When controlling the behavior of an actor, you can think of it as a classifier that sees a situation and takes a specific action.
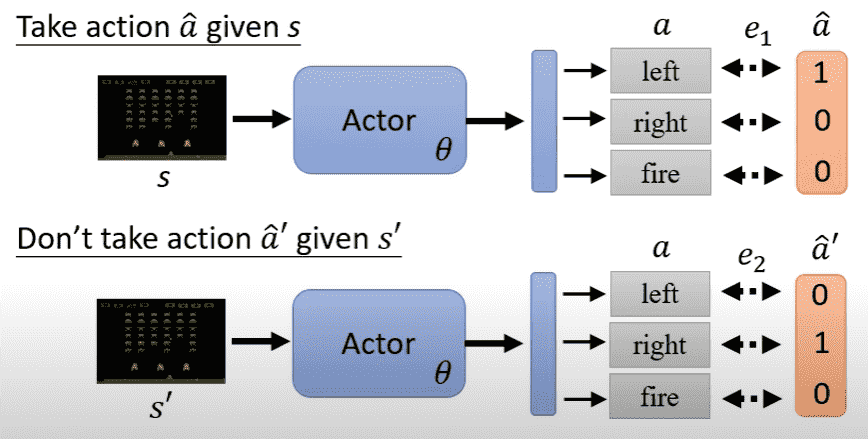
Both
Since e2 is about what not to do, the loss is calculated with a negative sign.
This allows you to write the total loss function by defining how good or bad each behavior is:
| +1.5 | |
| -0.5 | |
| +0.5 | |
| -3 |
(important)How to define
A short-sight version:
Defining

This method is too eager for quick success, sometimes the local optimal solution may be very unfavorable to the overall situation, and sometimes the appropriate abandonment of some small benefits can ultimately obtain the most rewards.
version1
This method adds up all the rewards for selecting an action (i.e., what the outcome of the action was). Use the effect of the sum to determine
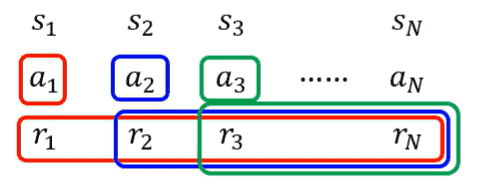
This approach is not good enough. If the whole process is long, we cannot simply attribute the reward
version2
The introduction of a attenuation factor indicates that the farther away from
version3
Good and bad are relative, and if the rewards are all non-negative, then
Minus baseline
All
| Pseudocode of policy gradient |
|---|
| initialize actor network parameters for training iteration using actor obtain data compute compute loss |
Unlike the general model, the process of collecting data is within the for loop, that is, its data is dynamically collected along with the training.
In this process, each set of data can only update the parameter once, and the next time the parameter is updated, new data comes in. That's why RL training is slow.
A set of environments is only suitable for updating certain parameters, and if it is used to update other parameters, it may cause a bad effect. The so-called: his honey, my arsenic.
Exploration
The actor interacting with the environment should be made as random as possible, because this allows for as many effects of different behaviors as possible. This can be done by increasing entropy or directly adding noise to the parameters, making it easier for actors to take low-probability actions.
math: How to calculate gradient?
we know that
and
Calculating the
so how can we find
Since the gradient of
therefore,
using formula:
This gradient can not be calculated directly at this stage, so it is necessary to sample
using Pytorch or TF, we can do it conveniently:
if add a baseline, the gradient becomes:
Imagine a situation where the first step was a very good decision, but the second step was wrong and the final score is not so good, but the score is still good because the first step was well done, then the model mistakenly believes that the second step is also good.
If you apply the calculation method in version2, you should not use the overall R to calculate the correctness of a certain step, but should calculate the sum of rewards after this step, so as to avoid the problems raised above:
Then further, directly using the method of version3 combined with the attenuation factor to calculate, we can get the final gradient expression:
On policy v.s. Off-policy
If the actor to train and the actor for interacting is the same, we call it on-policy. In other words, if the actor himself does training to gain experience, it is on policy; if the actor gains experience by watching other actors train, it is off-policy.
An advantage of off-policy is that it can be trained with the experience of other actors, so there is no need to constantly collect data, which can greatly improve the training efficiency.