

神经网络与深度学习实验三实验报告
神经网络与深度学习实验三实验报告
题目一
实验目的
用变分自编码器生成MNIST手写数字,实现以下要求:
推荐使用高斯分布随机初始化模型参数,可以避免一部分模式坍塌问题。
1、模型架构:
① 编码器(全连接层):
输入图片维度:784(28×28)
输出层维度(ReLU):400
② 生成均值(全连接层):
输入层维度:400
输出层维度:20
③ 生成标准差(全连接层):
输入层维度:400
输出层维度:20
④ 使用均值和标准差生成隐变量z
⑤解码器(全连接层):
输入维度:20
隐藏层维度(ReLU):400
输出层维度(Sigmoid) :784
训练完网络,需要提交重构损失和KL散度的随迭代次数的变化图,以及10 张 生成的手写数字图片。
实验过程
模型
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
# 按要求布置每层的规模
self.fc1 = nn.Linear(784, 400)
self.fc2_mean = nn.Linear(400, 20)
self.fc2_logvar = nn.Linear(400, 20)
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
def encode(self, x):
h1 = torch.relu(self.fc1(x))
return self.fc2_mean(h1), self.fc2_logvar(h1)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h3 = torch.relu(self.fc3(z))
return torch.sigmoid(self.fc4(h3))
def forward(self, x):
mu, logvar = self.encode(x.view(-1, 784))
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar训练、画图部分见代码。
生成数字
with torch.no_grad():
z = torch.randn(10, 20)
sample = model.decode(z).cpu()
plt.figure(figsize=(15, 2))
for i in range(10):
plt.subplot(1, 10, i + 1)
plt.imshow(sample[i].view(28, 28), cmap='gray')
plt.axis('off')
plt.show()实验结果
模型可以满足实验要求,有如下的重构损失和KL散度的随迭代次数的变化图:

以及十张生成的手写数字:

题目二
实验目的
使用Transformer解决命名实体识别(Named Entity Recognition)任务。
任务:命名实体识别(Named Entity Recognition,简称NER)是自然语言处理领域的基础任务之一,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。下图举了一个NER的例子,对人类来说识别出“南京市”和“长江大桥”是比较简单的任务,但是对模型来说却有可能识别出错误的实体。
模型:近年来,以Transformer为基础的深度学习模型在自然语言处理和视觉领域盛行。此次作业旨在熟悉Transformer的原理及调用。推荐使用python库transformers来载入以及训练一个transformers模型。具体的模型采用bert-base-cased作为编码器,全连接层用于分类。
数据集:CoNLL2003 CoNLL2003共包含4种实体类别,分时是location(地点名),organization(组织名),person(人名)和 miscellaneous(杂项)。此外,不属于任何实体类别的单词应该被标注为O(其他)。以下为示例:
示例输入:Japan began the defense of their Asian Cup title with a lucky 2-1 win against Syria in a Group C championship match on Friday
真实标签:B-location O O O O O B-misc I-misc O O O O O O O B-location O O O O O O O O O
说明:实体类别前的B-/I-表示Begin和Inside,实体的第一个词应该以B-开头,实体后面的词应该以I-开头。例如Asian Cup的Asian标注为B-misc,Cup则标注为 I-misc。
任务
① 阅读提供的代码,补充TODO位置的代码:
class BertTagger(nn.Module):
def __init__(self, hidden_dim, output_dim, model_name):
super(BertTagger, self).__init__()
# TODO:
# (1)利用AutoConfig.from_pretrained定义config
# (2)利用AutoModelWithLMHead.from_pretrained定义模型,注意要传入刚才的config
# (3)定义一个线性层用于分类预测
# 提示:参考文档https://huggingface.co/bert-base-cased
config =
self.bert_model =
self.classifier =
def forward(self, X):
# TODO:
# (1)把X输入bert_model得到hidden_states;
# (2)提取其中属于最后一个transformer layer的hidden_states作为最终特征;
# (3)最后把特征输入线性层完成预测。
# 提示:需要用到output_hidden_states参数,并参考以下文档
# https://huggingface.co/docs/transformers/v4.21.2/en/model_doc/bert#transformers.BertLMHeadModel
features =
logits =
return logits② 利用main.py训练一个NER模型,记录并可视化训练过程,比如loss,f1;
③ 训练结束后,利用predict.py载入保存的模型,并输入自定义的例子进行 预测,分析模型的输出结果;
④ 回答思考题:
(1) CoNLL2003有4种实体类型,为什么输出的维度是9?
(2) 为什么需要额外加线性层用于预测,而不用transformers模型原有自带的线性层?
(3) 在predict.py当中,tokenizer的作用是什么?
(4) 在predict.py当中,mask的作用是什么?
⑤ 扩展(选做):说明现有模型不足之处并改进模型,展示改进模型的性能。比如,增加CRF层。
实验过程
任务①
def __init__(self, hidden_dim, output_dim, model_name):
super(BertTagger, self).__init__()
config = AutoConfig.from_pretrained(model_name, output_hidden_states=True)
# AutoConfig.from_pretrained 是从 Hugging Face 的模型库加载指定的 BERT 配置
# output_hidden_states=True 确保在前向传播时会输出所有层的隐藏状态
self.bert_model = AutoModelForTokenClassification.from_pretrained(
model_name, config=config
)
#加载预训练模型时只需传模型名称和配置
self.classifier = nn.Linear(config.hidden_size, output_dim)
# 用于分类的线性层,将 BERT 输出的特征转换为类别标签的logitsAutoModelForTokenClassification.from_pretrained会把模型的权重从 Hugging Face 的模型库下载到本地缓存文件夹~/.cache/huggingface/transformers 中,并生成检查点。
第一次运行时,模型和配置会从 Hugging Face 下载到本地缓存,需要挂梯子,后续运行过程不再需要联网。
# 前传
def forward(self, X):
outputs = self.bert_model(X)
# 将输入 X 输入到 BERT 模型中,获取输出 outputs
hidden_states = outputs.hidden_states
features = hidden_states[-1]
# 选择最后一层的隐藏状态,作为最终特征表示
logits = self.classifier(features)
# 将提取的特征 features 输入到线性分类层 classifier,得到 logits,这是每个标记的类别概率分布
return logits任务②
直接运行main.py即可。但是有报错:
Parameter 'Loader' unfilled经查,在config.py中用到了
yaml.load(f)在较新的yaml版本中,要求在这个方法中额外传一个Loader:
config = yaml.load(f, Loader=yaml.FullLoader)更改后可以开始训练。
每个 epoch 都会训练一个模型的副本。在每个 epoch 开始时,模型的参数会根据前一个 epoch 的学习结果进行初始化和更新。在每个 epoch 结束时,会对验证集进行评估并计算 F1 分数:
if e % params.evaluate_interval == 0:
f1_dev, f1_dev_each_class = trainer.evaluate(dataloader_dev, each_class=True)
logger.info("Epoch %d, Step %d: Dev_f1=%.4f, Dev_f1_each_class=%s" % (
e, step, f1_dev, str(f1_dev_each_class)
))最终得到的loss-f1图见实验结果部分。
可见经过10个epoch最终得到了准确率和召回率相当高的模型,它已经被保存在了本地default目录中。
任务③
直接运行predict,但是有报错:
TypeError: expected string or bytes-like object我尝试溯源这个错误,但是多次检查都没有发现问题。后来我觉得可能是这段代码有需要向huggingface发送请求等待回应的代码,但是因为我没挂梯子所以没能及时填入str,导致了这个报错。后来挂上梯子再运行果然可以出结果了。但是尚不清楚为什么这样做可以,我的pth模型已经和配置都保存在本地,不知道为什么要发请求。
任务④
思考题解答见实验结果部分。
任务⑤
这个模型最大的不足之处就在于准确率不够高。先尝试在隐藏层和输出之间添加全连接层,并利用dropout防过拟合:
def __init__(self, hidden_dim, output_dim, model_name):
super(BertTagger, self).__init__()
config = AutoConfig.from_pretrained(model_name, output_hidden_states=True)
self.bert_model = AutoModelForTokenClassification.from_pretrained(model_name, config=config)
self.fc1 = nn.Linear(config.hidden_size, 512)
self.fc2 = nn.Linear(512, 256)
self.classifier = nn.Linear(256, output_dim)
self.dropout = nn.Dropout(0.3)
def forward(self, X):
outputs = self.bert_model(X)
hidden_states = outputs.hidden_states
features = hidden_states[-1]
features = self.dropout(features)
features = self.fc1(features)
features = torch.sigmoid(features)
features = self.fc2(features)
features = torch.relu(features)
logits = self.classifier(features)
return logits发现效果不好,相同的数据集和训练轮数下性能还不如之前,具体数据见实验结果。
查阅资料(arxiv-1508.01991)后,决定尝试lstm+crf。
lstm层主要在避免梯度爆炸和梯度消失方面解决了RNN在处理长句子时存在的问题,很适合用来做实体识别。它能通过特征抽取器对句子进行特征建模,主要还是crf在起作用。
在本次实验中,由于不能改动太多代码,所以只用bert+crf优化。
如果不加lstm,bert和crf层的学习率不要设成一样,让crf层学习率要更大一些(一般是bert的5~10倍),要让crf层快速收敛。
经典报错记录
TypeError: forward() missing 1 required positional argument: 'tags'这是因为在定义模型前传方法时,我们让labels参与了计算损失的过程,所以在训练时调用forward也必须加一个张量类型的labels。
把训练过程中的前传调用改为:
def batch_forward(self, inputs, labels):
self.logits = self.model.forward(inputs, labels)还是有报错:
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.查资料发现这种报错是因为输出维度和分类数目不一致。

但是检查之后并没发现问题。后来发现原来是标签y有问题,本来分9类,应该只有0-8,但是输出后发现y的最小值竟然达到了-100。我没有深究是个别错误还是什么,直接把全部的小于0的值都改成0:
y[y < 0] = 0改完后果然不再报错。
但是又有一个问题,在评估阶段的
correct_cnt += int(torch.sum(torch.eq(torch.max(trainer.logits, dim=2)[1], y).float()).item())这一行,他说我的trainer.logits是一个tuple:
TypeError: max() received an invalid combination of arguments - got (tuple, dim=int), but expected one of:
* (Tensor input)
* (Tensor input, Tensor other, *, Tensor out)
* (Tensor input, int dim, bool keepdim, *, tuple of Tensors out)
* (Tensor input, name dim, bool keepdim, *, tuple of Tensors out)它既然要tensor,那我就在forward函数里返回之前把它强制转换为tensor类型:
if labels is not None:
loss = -self.crf(logits, labels, reduction='mean')
return torch.tensor(logits), loss
# 将提取的特征 features 输入到线性分类层 classifier,得到 logits,这是每个标记的类别概率分布
return torch.tensor(logits)结果还是不行,我发现在有标签的情况下竟然返回了两个值,其实只返回loss就行。删掉logits后又有新报错:
correct_cnt += int(torch.sum(torch.eq(torch.max(trainer.logits, dim=2)[1], y).float()).item())
IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 2)还是数据格式的问题,挨个检查调整。
2024年11月3日20:19:39
很遗憾,我尝试了各种能想到的方法,也咨询了实验室的师兄,按他的建议修改了推理部分有关解码的部分代码,都没能解决问题。我现在初步怀疑是我crf包出了问题,如果想解决就必须从头开始改包。由于我最近时间实在有限,这个部分暂时搁置。
i
关于crf和lstm的详细原理这里先不做说明,后续会更新专门的帖子讲解其中的具体数学原理。
实验结果
任务①、②
经检验,#TODO部分填写正确,能够正确输出loss和f1值:

任务③
输入句子:
sentence = "China 0 - 7 loss to Japan in a 2026 World Cup qualifier has become the biggest talking point in sports these days"输出的实体序列:
['B-location' 'O' 'O' 'O' 'O' 'O' 'B-location' 'O' 'O' 'O' 'B-misc' 'I-misc' 'O' 'O' 'O' 'O' 'O' 'O' 'O' 'O' 'O' 'O' 'O']分析:
模型识别出的实体有:
{
"B-location": ['China', 'Japan'],
"B-misc": 'World',
"I-misc": 'Cup'
}识别完全正确。
任务④
(1) CoNLL2003有4种实体类型,为什么输出的维度是9?
答:因为CoNLL2003使用BIO标注法,每种实体都单独标注了开头和结尾,并单独标注出了非实体这一类别,一共就是
(2) 为什么需要额外加线性层用于预测,而不用transformers模型原有自带的线性层?
答:额外添加线性层用于预测是为了使模型在特定任务上能够进行自定义的输出,将模型的输出维度调整为与标签数(9)相匹配的维度。
(3) 在predict.py当中,tokenizer的作用是什么?
答:tokenizer的作用是将原始文本编码为模型可以理解的格式,它通过分词器拆分并编码单词,并给原始文本插入定界符如[cls]等。在使用nlp模型时必须定义tokenizer,一般就是用自动分词器。
(4) 在predict.py当中,mask的作用是什么?
答:mask主要是用来指示模型在处理输入时,要关注哪些部分、忽略哪些部分。
比如在构建mask_list时:
mask_list = []
for word in word_list:
subs_ = auto_tokenizer.tokenize(word)
if len(subs_) > 0:
token_list.extend(auto_tokenizer.convert_tokens_to_ids(subs_))
mask_list.extend([True] + (len(subs_) - 1) * [False])如果一个单词被分词成多个子词,那么模型将忽略后面的子词填充。
任务⑤
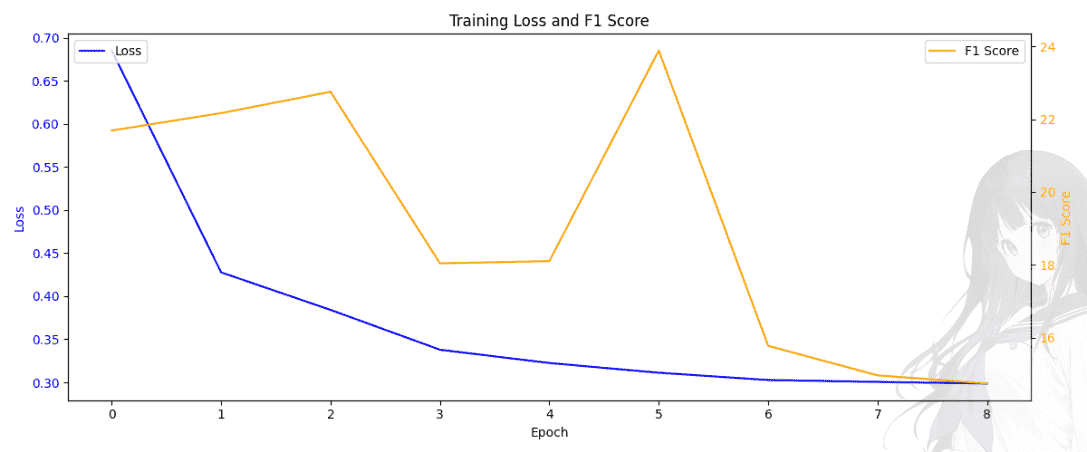
简单地增加全连接层得到的性能:
2024年11月3日20:15:22
很遗憾,我尝试了各种能想到的方法,也咨询了实验室的师兄,按他的建议修改了推理部分有关解码的部分代码,都没能解决问题。我现在初步怀疑是我crf包出了问题,如果想解决就必须从头开始改包。由于我最近时间实在有限,这个部分暂时搁置。
总结与思考
通过这次实验,我对深度学习、尤其是NER模型有了更深刻的理解。在实验过程中遇到的各种问题也提升了我处理bug的能力,另外我也明白了衡量分类模型的指标f1值的概念,知道了单纯用accuracy评价模型是不够客观的。在做选做题的过程中,我通过自己摸索、查询资料成功地提高了模型的性能,这让我优化模型的能力大大提高,在日后遇到相关问题时我能够独立解决。总之这次实验让我受益匪浅,让我对很多知识的理解不止停留在纸面。