

实验室项目记录——寻找触发词
实验室项目记录——寻找触发词
实验目的
之前利用llm构造触发器的方法效果还不错,命中率能达到1/5左右。现在有一个新的方法,具体见前置准备章节。最终的目的是利用这种新的方法提高实体识别的命中率。而我现在要做的是构造出数据集。
前置准备
论文精读
本次主要参考:AlignRE: An Encoding and Semantic Alignment Approach for Zero-Shot Relation Extraction,
略过具体细节,这里用图来解释原理:
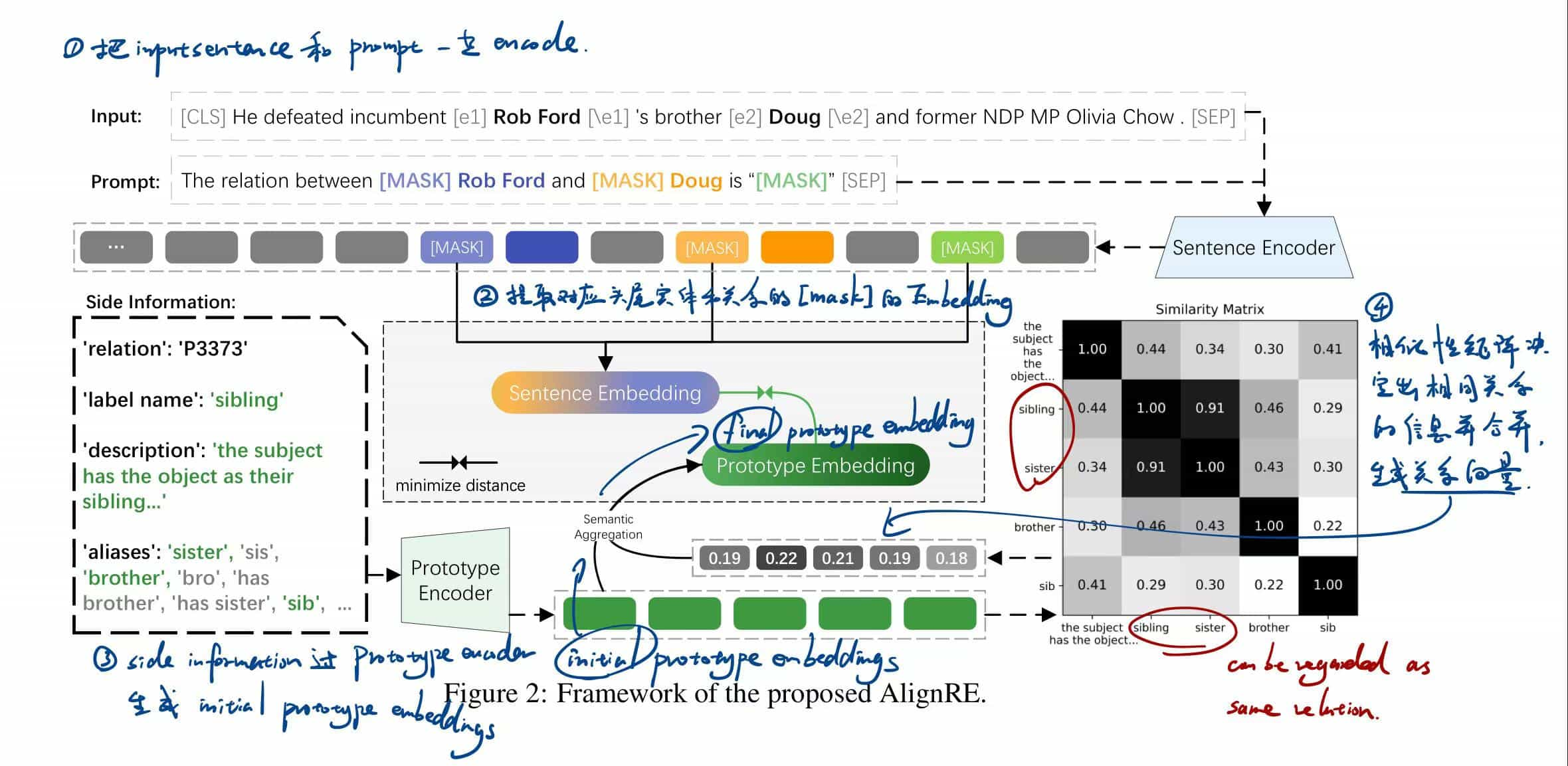
传统方法是把关系直接做embedding,之后和句子的向量一起放到特征空间里比较。但是这样会忽略大量的关系辅助信息,并且在原型和句子之间存在显著的编码差距,从而限制性能。
这篇文章里提到的方法分为以下步骤:
先生成Sentence embedding:
① 给输入句子
② 用头尾实体和关系的[mask]生成统一的prompt模板:
这个prompt是唯一的,一切关系都可以用这一个prompt来抽,无需新做;
关于[mask]
顾名思义,[mask]其实就是一种遮蔽、替换或占位。这里是用三个[mask]替换掉prompt中的头尾实体和关系,做成这样的句子:“[mask]
③ 拼接prompt和输入句子:
其中
④ 算出输入句子
其中
Sentence embedding生成完毕,之后生成prototype embedding:
对于关系
⑤ 对所有side information编码,生成一组initial prototype embeddings:
⑥ 为每个side information分配权重,代表它们对决定关系的“重要性”。具体的分配方法是通过一个像图中展示的相似性矩阵,第
其中
最后可以得到一个权重向量
关于相似度矩阵
相似度矩阵决定出所有代表相同关系的信息,比如图中sibling和sister就属于相同关系,它们在确定"sibling"这个关系时的贡献显然是相近且是最大的。
⑦ 计算final prototype embedding:
这就是第
⑧ 比较两个embedding识别出关系。
代码精读
extract_mask函数用来提取出上面提到的三个[MASK],它的具体实现如下:
def extract_mask(sequence_output, e_mask):
extended_e_mask = e_mask.unsqueeze(-1)
extended_e_mask = extended_e_mask.float() * sequence_output
extended_e_mask, _ = extended_e_mask.max(dim=-2)
return extended_e_mask.float()对输入序列做处理,输出聚合后的实体/关系嵌入向量,形状为 (batch_size, hidden_dim)。
其中e_mask是实体或关系的掩码,形状为 (batch_size, seq_len),其中值为 1 的位置表示实体或关系的词,其他位置为 0。
模型定义在:
class AlignRE(BertPreTrainedModel)它继承了bert预训练模型作为主体网络。
前向传播中,输入如下的参数:
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
mark_head_mask=None,
mark_tail_mask=None,
mark_relation_mask=None,
input_relation_emb=None,
labels=None,
num_neg_sample=None,
extract_trigger_by_atten=True
):其中attention_mask是注意力掩码,用于区分实际输入序列和填充部分;output_attentions用于决定是否输出注意力权重。
前向传播函数输出两个值:sequence_output是bert模型最后一层的输出;attention_weights是注意力权重。
首先通过 BERT 提取句子中每个词的上下文表示:
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
output_attentions=extract_trigger_by_atten,
return_dict=True
)
sequence_output = outputs[0] # 获取每个词的上下文表示对应Sentence Encoder 部分,对句子编码后得到 sequence_output,其中每个 token 都有一个向量表示。
提取出头尾实体和关系的mask:
e1_mask = extract_mask(sequence_output, mark_head_mask)
e2_mask = extract_mask(sequence_output, mark_tail_mask)
relation_mask = extract_mask(sequence_output, mark_relation_mask)得到的就是理论部分中对应的
之后用注意力机制提取触发词,处理注意力权重:
# 遍历每一层的注意力权重
for layer_attention in attention_weights:
# layer_attention: (batch_size, num_heads, seq_len, seq_len)
for b in range(batch_size):
# 对每个样本的头实体、尾实体和关系注意力求平均
head_scores = layer_attention[b, :, head_indices[b], :].mean(dim=0) # 聚合多头注意力
tail_scores = layer_attention[b, :, tail_indices[b], :].mean(dim=0)
relation_scores = layer_attention[b, :, relation_indices[b], :].mean(dim=0)
# 累加注意力权重,之后会归一化,不用担心累加过多层造成数值过大
head_attention_scores[b] += head_scores
tail_attention_scores[b] += tail_scores
relation_attention_scores[b] += relation_scores这里求出的权重是每个样本中头实体、尾实体和关系位置的注意力权重的平均值的和,经过归一化可以得到头尾实体和关系的注意力分数,将来会参与与initial prototype embedding一起合成final prototype embedding。
在输入中 [MASK] 的位置可能对应关系的触发词,让它们的注意力权重更高可以帮助模型更加关注这些位置。
在data_process文件中记载了生成final prototype embedding的详细过程:
在sentence_bert_prototype函数中,SentenceTransformer 提取出关系的描述文本、标签名称和别名的语义嵌入;最终通过加权平均 (weight_mean) 构造Prototype Embedding并放入emb_dict返回。
之后拼接输入句子和prompt:
def __getitem__(self, idx):
single_data = self.data[idx]
pos1 = single_data['h']['pos'][0]
pos2 = single_data['t']['pos'][0]
words = single_data['token']
# 根据实体位置调整掩码与标记符号
if pos1 < pos2:
new_words = words[:pos1] + ['#'] + words[pos1:pos1_end] + ['#'] + words[pos1_end:pos2] \
+ ['@'] + words[pos2:pos2_end] + ['@'] + words[pos2_end:]
else:
...
sentence = " ".join(new_words)
# 构造 Prompt,明确实体和关系
prompt = "The relation between [MASK] {} and [MASK] {} is \"[MASK]\"".format(
" ".join(words[pos1:pos1_end]),
" ".join(words[pos2:pos2_end]))这个拼接过程很清楚,不多赘述。
拼接完成后得到的就是
tokens_info = self.tokenizer(sentence, prompt)
input_ids = tokens_info['input_ids']
attention_mask = torch.tensor(tokens_info['attention_mask'])
token_type_ids = torch.tensor(tokens_info['token_type_ids'])
# [MASK] 对应的 token_id
mask_idx = [index for index, value in enumerate(input_ids) if value == 103]
mark_head_mask, mark_tail_mask, mark_relation_mask = \
mark_entity_and_mask(
mask_idx,
len(input_ids)
)利用 AutoTokenizer 对输入序列进行分词并生成 input_ids、attention_mask 和 token_type_ids,用的掩码 mark_head_mask、mark_tail_mask 和 mark_relation_mask 标识实体和关系的位置。
把这里生成的embedding和上边的prototype embedding作比较即可进行关系抽取。
实验过程
这个任务主要分两部分,一是要找一个分词粒度较大的分词器,对句子进行分词;二是后续操作:对句子进行分词,除了prompt和实体外,每一次mask一个短语,然后通过模型计算相似度;最后对所有mask的组合做一个结果相似度排序,找出影响最大的词。
挑选分词器
这一步需要一个大分词粒度的分词器,这是因为最后在决定各个部分的贡献时肯定是要识别出短语的,如果按词来分的话就太细了,不好做mask,识别出的结果也没有意义。
这里我选择Spacy,可以通过合并短语为单个Token来实现在分词过程中保留短语:
with doc.retokenize() as retokenizer:
for chunk in doc.noun_chunks:
retokenizer.merge(chunk) # 将名词短语合并为单个 Token比如输入:
Natural language processing is a key area of artificial intelligence.分词结果是:
['Natural language processing', 'is', 'a key area', 'of', 'artificial intelligence', '.']可见,相比于word级的分词,它的粒度明显要大很多。
2024年11月22日21:37:01
进行下一步时,我遇到如下待解答的问题:
1、分词时是对数据集的text部分做分词吗?如果不是,对谁做分词?
2、每次mask一个短语这件事如何自动化地实现(这个事我可以自己解决但暂时没去想)?
3、mask后计算谁和谁的相似度?如何计算?(个人理解是每一个mask的组合都做成Sentence embedding,之后算和prototype embedding的相似度,相似度最低的组合中被mask掉的短语就是对决定关系影响最大的。但是这样得到影响最大的一个短语有什么用处?)
4、既然目的是构造数据集,那最后要做成一个什么格式的东西?如果按我上边的理解,对于数据集中的每一个句子都只能得到一个或一些对决定关系影响最显著的短语,最后是要把这些短语放进数据集中吗?
我发现这个任务和论文中的做法有些出入,所以对一些具体的做法有疑惑,待讨论,暂时搁置。
2024年11月26日17:40:42
今天解答了上边的问题:
1、只需对text做分词,因为prompt其他部分都一样;
3、mask后直接输入给模型让它做预测,看看和目标关系的相似度有多少,最后用evaluation文件中evaluate函数计算相似度。这里得到的“对识别关系影响最大的词”其实就是之前说的触发器。
4、最后取出对关系影响排前三的三个短语,一起放到数据集里。
自动化mask
这一步我需要做一个自动化的脚本来挨个mask东西,分词之后是一个列表,遍历这个列表每次mask掉一个词即可:
def auto_tokenizer(texts):
result = []
nlp = spacy.load("en_core_web_sm")
for text in texts:
tokens = []
doc = nlp(text)
with doc.retokenize() as retokenizer:
for chunk in doc.noun_chunks:
retokenizer.merge(chunk)
tokens = [token.text for token in doc]
result.append(tokens)把所有的text做成列表输入,它会把分词结果放到result返回。
但是我发现这么干有点多此一举,新的做法是直接遍历那个数据集,每遍历到一个text就立刻处理,之后把新的token写回文件里和token同级的位置:
def process_json(input_file, output_file, produce):
"""
读取 JSON 文件,处理 text 字段生成 new_token 字段,并写回到相应位置。
:param input_file: 输入的 JSON 文件路径
:param output_file: 处理后的 JSON 文件保存路径
:param produce: 用于处理 text 字段生成 new_token 的函数
"""
# 读取 JSON 文件
with open(input_file, 'r', encoding='utf-8') as f:
data = json.load(f)
# 遍历 JSON 数据的每个 key
for key, records in data.items():
for record in records:
# 确保 record 中有 text 字段
if 'text' in record:
# 使用 produce 函数处理 text 并生成 new_token
record['new_token'] = process(record['text'])
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
input_file = 'fewrel_dataset_llm_trigger_new.json'
output_file = 'fewrel_dataset_llm_trigger_new_with_new_token.json'
process_json(input_file, output_file, process)这样就构造好了粗粒度分词的数据集。下一步要做的就是遍历这个数据集,找出所有new_token,挨个mask掉里面的元素后喂给模型,看看谁的影响最大(去掉谁之后相似度最低)。
本来我想着找找有没有现成的推理代码,但是没有。所以我要自己做一个。
编写推理和评估代码
目标
这一步可以抽象为一个黑盒,输入分词后,mask过的token列表和期望的关系,输出这个token表和期望关系的相似度。
实现
首先,我们已经有了所有关系的原型映射:
prototype_file = "data/fewrel_train_stsb-bert-base.json"之后在输入的分词结果中进行mask:
# 1. 获取可以mask的词语集合,从(fewrel_dataset_llm_trigger_new_with_new_token)中选择(排除主体和客体)
mark_groups = get_mask_groups(example)
# 2. 决定本轮mask的词
mark_item = mark_groups[0]
# 3. 将mask的词语替换成 [MASK] ,并重新计算主体和客体在mask句子后的位置
sentence = ' '.join(example['token'])
sentence = sentence.replace(mark_item, MASK_FLAG)
mask_tokens = sentence.split(' ')之后直接放进预测函数中就能得到预测结果:
model_path = 马赛克
tokenizer = AutoTokenizer.from_pretrained(model_path)
predicted_relation, confidence_scores = predict_relation_with_similarity(
args, mask_example ,prototype_file, tokenizer, use_label=True)这样就写完了框架,应该可以看出重点在于怎么编写predict_relation_with_similarity函数。
i
这里的代码有点复杂之后再说,最近事多先写到这里。
实验结果
经过测试对于同一组输入,mask前后和目标关系的相似度略有下降,证明mask掉单词的方法确实能做到识别出谁对关系确定的影响最大:
// mask前
Predicted Relation: P931
Confidence Scores:0.2433006763458252
// mask后
Predicted Relation: P931
Confidence Scores: 0.24244746565818787