
Embedding
Embedding
Objectives
Deep learning models can handle semantics by vectorizing natural language.
General idea
Convert sequences or words which have similar meaning to vectors, and those vectors have short distance in high dimension space.
Encoder-Decoder Models
Encoders convert a practical problem into a mathematical problem, and decoder, in contrary, figure out mathematical problem and convert the result into natural language.
Two processes
They process textual content into semantically rich, vectorized representations.
Query Embedding
Designed for embedding shorter-form or question-like material, such as a simple statement or a question. Provide keywords that are dynamically embedded as needed, compared to document embedding.
Document Embedding
Tailored for longer-form or response-like content, including document chunks or paragraphs. The document is embedded during preprocessing and stored in a vector library for query.
Example
queries = [
"What's the weather like in Rocky Mountains?",
"What kinds of food is Italy known for?",
"What's my name? I bet you don't remember...",
"What's the point of life anyways?",
"The point of life is to have fun :D"
]
documents = [
"Komchatka's weather is cold, with long, severe winters.",
"Italy is famous for pasta, pizza, gelato, and espresso.",
"I can't recall personal names, only provide information.",
"Life's purpose varies, often seen as personal fulfillment.",
"Enjoying life's moments is indeed a wonderful approach.",
]%%time
# Embedding the queries
q_embeddings = [embedder.embed_query(query) for query in queries]
# Embedding the documents
d_embeddings = embedder.embed_documents(documents)You can directly vectorize the query and documents by calling embed_query and embed_documents, and their output is a list (vector).
After vectorization, the document and query can be checked for similarity:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import cosine_similarity
def plot_cross_similarity_matrix(emb1, emb2):
# Compute the similarity matrix between embeddings1 and embeddings2
cross_similarity_matrix = cosine_similarity(np.array(emb1), np.array(emb2))
# Plotting the cross-similarity matrix
plt.imshow(cross_similarity_matrix, cmap='Greens', interpolation='nearest')
plt.colorbar()
plt.gca().invert_yaxis()
plt.title("Cross-Similarity Matrix")
plt.grid(True)
plt.figure(figsize=(8, 6))
plot_cross_similarity_matrix(q_embeddings, d_embeddings)
plt.xlabel("Query Embeddings")
plt.ylabel("Document Embeddings")
plt.show()This code makes a comparison and generates a cross-similarity matrix:

The color represents the similarity of the corresponding entries on the two axes.
Misusing embed_query and embed_document may or may not result in very different results. For example, if you set both functions in the above example to embed_query, you'll get a slightly different result:
plt.figure(figsize=(8, 6))
plot_cross_similarity_matrix(
q_embeddings,
[embedder.embed_query(doc) for doc in documents]
)
plt.xlabel("Query Embeddings (of queries)")
plt.ylabel("Query Embeddings (of documents)")
plt.show()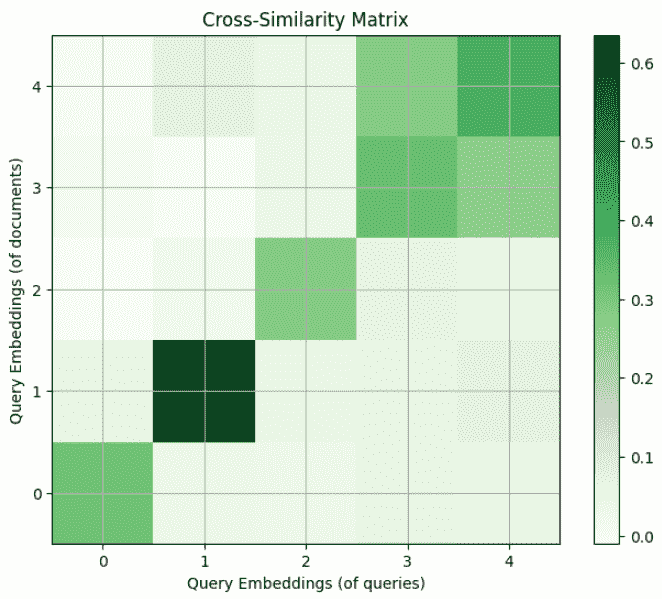
Generate a long, formatted answer
from langchain_nvidia_ai_endpoints import ChatNVIDIA
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from operator import itemgetter
expound_prompt = ChatPromptTemplate.from_template(
"Generate part of a longer story that could reasonably answer all"
" of these questions somewhere in its contents: {questions}\n"
" Make sure the passage only answers the following concretely: {q1}."
" Give it some weird formatting, and try not to answer the others."
" Do not include any commentary like 'Here is your response'"
)
# 给定问题列表questions和问题q1,生成的故事中要回答所有问题列表里的问题,但是只具体回答q1. 回答要具有奇怪的格式,并避免回答其他问题。
expound_chain = (
{'q1' : itemgetter(0), 'questions' : itemgetter(1)} # 把输入的列表填入字典
| expound_prompt # 把列表填入prompt
| instruct_llm # 把prompt喂给llm
| StrOutputParser() # 把llm的输出给parser规范化
)
longer_docs = []
# 这个列表用来存所有的输出文档(故事),应该有5个。
for i, q in enumerate(queries):
longer_doc = ""
longer_doc = expound_chain.invoke([q, queries])
pprint(f"\n\n[Query {i+1}]")
print(q)
pprint(f"\n\n[Document {i+1}]")
print(longer_doc)
pprint("-"*64)
longer_docs += [longer_doc]This code generates a long story response based on the query.
[Query 1]
What's the weather like in Rocky Mountains?
[Document 1]
Weather in the Rocky Mountains can be as unpredictable as a cat on a hot tin roof. One minute, it's all blue skies and sunshine, and the next, you're caught in a blizzard, wishing you had a Yeti for a coat. But generally, the summer months bring warm temperatures and plenty of outdoor activities like hiking, biking, and wildlife spotting. Winter, on the other hand, is a whole other ball game with skiing, snowboarding, and snowshoeing being the name of the game.
But seriously,
What's the weather like in Rocky Mountains? It depends on the time of year and elevation, but expect anything from hot and dry to cold and snowy. Now, about that life question, well, let's just say that's a bit more philosophical and complex than a simple answer can provide. As for Italian cuisine, have you tried real homemade pasta with a rich marinara sauce or pizza straight out of a wood-fired oven? Delizioso!
And your name? Oh right, how rude of me. How could I forget something so important? *wink*Different encoders may produce different results, for example, when encoding a document, one with the document type and one with the query type:
## At the time of writing, our embedding model supports up to 2048 tokens...
longer_docs_cut = [doc[:2048] for doc in longer_docs]
q_long_embs = [embedder._embed([doc], model_type='query')[0] for doc in longer_docs_cut]
d_long_embs = [embedder._embed([doc], model_type='passage')[0] for doc in longer_docs_cut]
## The difference for any particular example may be very small.
## We've raised the similarity matrix to the power of 5 to try and spot a difference.
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plot_cross_similarity_matrix(q_embeddings, q_long_embs)
plt.xlabel("Query Embeddings (of queries)")
plt.ylabel("Query Embeddings (of long documents)")
plt.subplot(1, 2, 2)
plot_cross_similarity_matrix(q_embeddings, d_long_embs)
plt.xlabel("Query Embeddings (of queries)")
plt.ylabel("Document Embeddings (of long documents)")
plt.show()
The selection of encoders remains to be learned.
The choice of dual encoder model and encoder is still to be studied.