

利用华为香橙派AiPro部署yolov5模型全程记录
利用华为香橙派AiPro部署yolov5模型全程记录
熟悉开发板
前言
这篇帖子用来记录大三上学期的智能系统选修课大作业,仍在完善中。
外观
这个东西和树莓派的板子没啥太大差别,我着重看了一下它的针脚图方便我之后加模块用。由于它没外壳,所以要注意一下别搞短路了。虽然我的桌垫并不导电,但是我说不准啥时候会撒点水在上边,所以稳妥起见还是立着放吧。

它本身是不带风扇的,老师贴心地在上边安了一个风扇。

可以看到上边那个片状物就是WiFi天线。其实它只要带WiFi,就跟普通的linux服务器一模一样了,啥都不用我自己配的程度,舒服。
针脚图如下,留在这里备用:
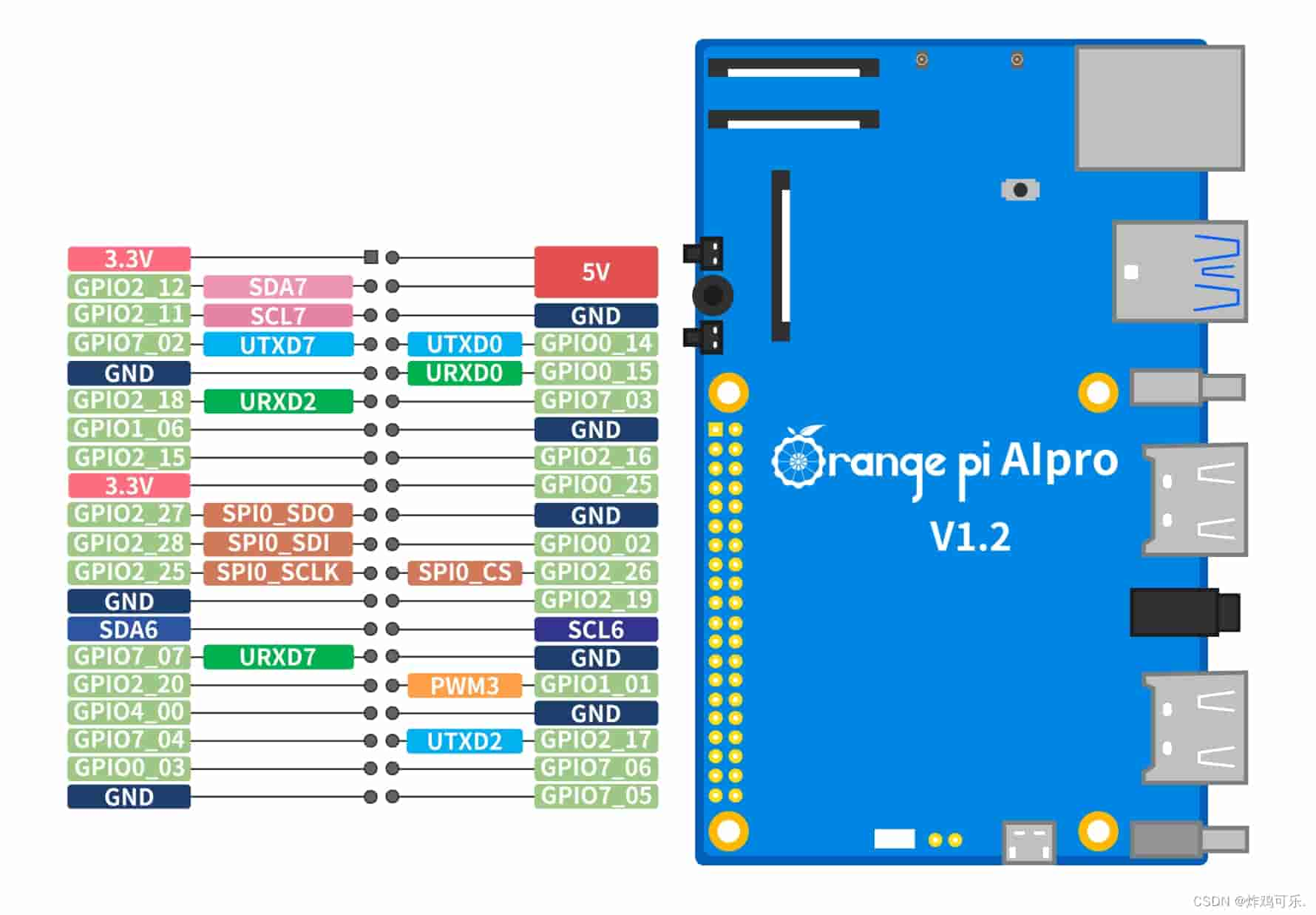
系统
网上都能查到的废话就不讲了,由于我之前做过树莓派相关的开发,所以也没花太长时间熟悉它。尤其是这块板子本身已经烧好了系统,开箱即用。老师也给我提供了烧录器,可能等我写好了实验报告能自己烧一遍系统试一下,现在就先不玩了怕给玩坏了。

用初始密码进入系统,连上WiFi后看一眼内网ip就可以拔了,用ssh连接:

非常顺利。ok,到这一步,这东西真就跟一个服务器一模一样了,可以开始进行部署工作。
这块板子上登着一个b站账号…等级和硬币都不少,我怀疑是它的历任使用者集体贡献的…
部署过程
yolo-v5样例测试
在自己搞之前我打算先测一下它自带的样例,确保这东西的环境没问题。在用户手册中可以找到它是自带jupyter和一个yolo-v5的样例的:

那还是先插上显示器测一下能用不能。
在图形界面终端输入
cd samples/notebooks/
./start_notebook.sh就能获得jupyter的链接,复制到浏览器启动即可(其实拿到token后也可以拔掉显示器去远程连接,但是插都插了就在本地测试吧)。

打开jupyter图形界面,找到main.ipynb直接运行:

这是一个识别赛车的模型,可以完美地用本地视频运行,说明环境没问题。下一步准备着手做垃圾分类模型。
选题
上策
我最好的设想是做一个带摄像头或语音模块的垃圾分类系统,摄像头识别到垃圾后由语音模块播放出这是什么垃圾,应该往哪扔。
中策
如果上边的实现不了,就砍掉扩展模块,直接搞一个yolo模型(实在不行我就找一个现成的om模型…)放在上边从本地输入图片做推理。但经过跟老师和精通嵌入式的同学交流,得知其实如果模型能跑通,加模块并非什么难事。
下策
如果连yolo都整不明白,我就干脆把它当服务器用,直接在上边部署一个可供远程访问的llm平台算了。但我觉得用开发板做这个实在是大材小用,有点太水了。
模型准备
目的
白嫖设计编写模型之前,要知道我们最后到底需要个啥东西。首先需要数据集并写训练代码,训练出一个.om格式的模型(这种格式是最适合香橙派去推理的),之后再用这个模型去拼接其他的模块。
准备训练数据集
数据集的构造可以手动来,找一堆图片之后利用labelImg手动做标注,然后转换一下格式,确保每一张图片都对应一个.txt格式的标签。但是垃圾分类这种选题很常见,所以我可以直接去找现成标好的数据集。
垃圾分类的数据集非常多,我这里选用开源工具中的生活垃圾数据集:
克隆到本地:
git clone https://gitcode.com/open-source-toolkit/875cd.git由于这里是rar格式的压缩包,所以在解压前要先安装unrar,再解压:
unrar x ImageSet.rarx代表以绝对路径解压。
这个数据集是已经划分好训练、验证和测试集的,分别放在:
train: /home/HwHiAiUser/samples/notebooks/waste_classify/ImageSet/data-txt/train.txt
val: /home/HwHiAiUser/samples/notebooks/waste_classify/ImageSet/data-txt/val.txt
val: /home/HwHiAiUser/samples/notebooks/waste_classify/ImageSet/data-txt/test.txt训练过程中只需要前两个。
之后写配置文件放在数据集内,告诉模型数据集的基本信息:
# myvoc.txt
train: G:\yolov5\data\ImageSet\images\train
val: G:\yolov5\data\ImageSet\images\val
# number of classes
nc: 4
# class names
names: ["recyclable waste", "hazardous waste", "kitchen waste", "other waste"]大坑警告
在这一步,有些教程可能会告诉你路径要写图片目录的路径,指向一个.txt格式的目录文件,比如这样:…/ImageSet/data-txt/val.txt,但这是完全不对的!yolo有两种数据组织方式,如果在images和label两个文件夹中划分好了训练集和测试集,路径就应该直接指向带图片的文件夹。
获取anchors
这里我不太确定是否需要手动获取,就先不弄了,后续有问题再回来看。
模型训练
既然最后我需要的只是一个om格式的模型,那我就现在windows下训练它,毕竟开发板用起来还是没win熟。
yolov5安装
创建虚拟环境
conda create -n yolov5 --clone Machine_learning因为我在Machine_learning这个环境里装了torch-gpu,所以直接在这个基础上进行了。由于我当时没有先见之明,什么包都往里装,并没有把torch独立出来,导致这个克隆是个及其漫长的过程。
注意
这里python版本必须高于3.10.
下载源码
git clone https://github.com/ultralytics/yolov5下载预训练模型
用这个链接下载预训练模型,这一步主要是为了验证安装是否正确和安装必要的包。
其中 yolov5s 目标检测速度最快,因为其网络参数最少,但相应的,检测效果相比是最差的;而 yolov5x 是检测效果最好的,参数最多,而时间上最慢。这里就选一个yolov5m做测试。
下载完的模型是.pt格式。
安装所需模块
这里只需要:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple即可。另外,由于Requirements中要安pytorch,这一步可能有点恶心,如果希望用gpu版的话还是建议复制自己已有的环境来继续下一步,不要重新装。
不过作为备用,我还是完全按要求装了一个环境,免得有那种很严苛的版本要求导致后期出幺蛾子。
测试
把图片保存在yolov5/data/images中,运行detect.py,加上--source 相对路径参数,就可以在yolov5/runs/detect里找到识别后的图片。如果能识别成功,就算装完了。
原图(yolo自带):

识别结果:

没错,就是这么强。
开始训练
在按上边配置好数据,写好myvoc.yaml文件后,其实训练就变得相当无脑。
注意
train和val图片文件夹必须放在yolov5/images文件夹中,不然会报错。
你只需运行它写好的train.py即可。关于参数怎么写,在文件里有格式。我用的训练命令是:
python train.py --weights weights/yolov5s.pt --cfg models/yolov5s.yaml --data data/myvoc.yaml --epoch 200 --batch-size 8 --img 640 --device 0如果用cpu训练,最后一个参数应改成cpu。
在尝试时你可能会发现,所谓的训练其实就是在对现有的模型做微调,也就是把原有的数据标签换成你自己指定的,所以训练速度和准确率会比重新训练快很多。
如果上边的过程都是对的,这里不会有阻碍,会自动开始训练:

取决于硬件的能力,跑这玩意时间不一定。
训练结束后,会被保存在runs/train/weights/下,这个路径是由参数--weights指定的。
今天先写到这,今晚通宵挂,模型的推理工作等白天放到板子上去做。其实有了模型跑通了之后就已经完成了,剩下都算锦上添花。
2024年11月9日00:25:24
事实上我是不会傻呵呵用自己电脑上的破T1200卡干这个事的,我手里有两个学院的不限额计算平台账号,此时不用更待何时?学校的服务器不让联网,但这完全难不倒我,我花了点时间加了一些魔法绕过了这个限制,具体咋做的就不说了。来体会一下2张A800显卡488G显存并行训练的恐怖速度:


虽然这多少有点不太好,但你不说谁会在意呢。
2024年11月9日10:02:06
来看一下昨晚的训练效果:
标签种类和面积大小形状的分布可视化图:
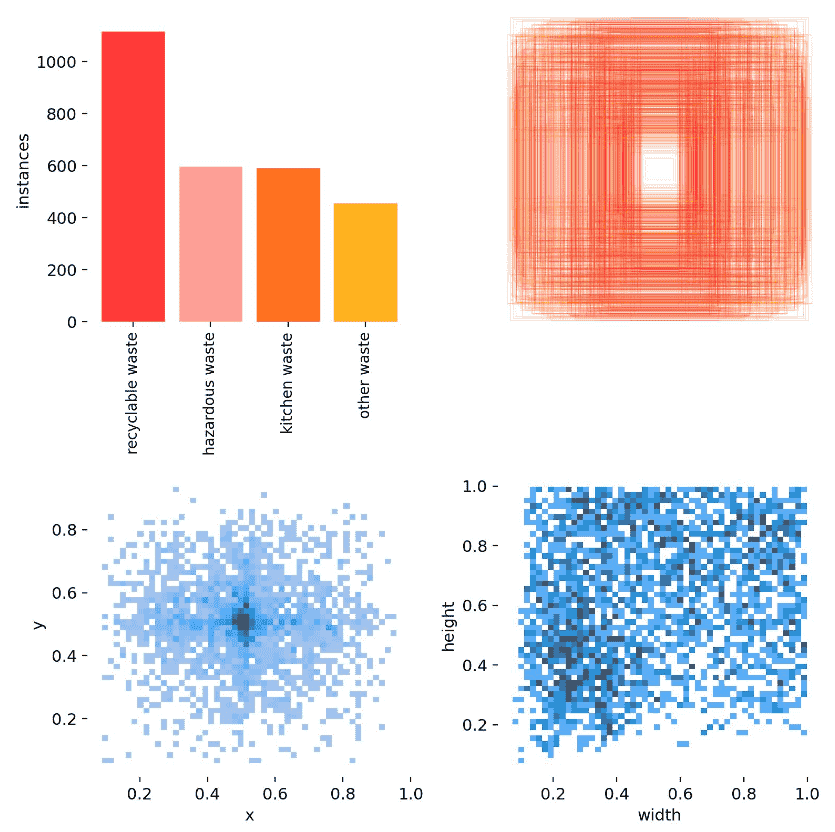

这是最后一代的batch2给出的一张图片,可以看出效果其实很不错了已经。但是要保证它可靠没有过拟合,还是自己测一下。
模型测试
测试指令:
python detect.py --weights runs/train/exp14/weights/best.pt --source ../data/1.jpg测试图片和结果:

效果很不好。我怀疑做完我训练方式不对或者它中途退出了,今天重新来一遍试一下。
第二次测试
2024年11月9日11:12:41
在确保训练方法没有问题的情况下进行第二次测试:
测试集的表现:


我发现这个模型对背景要求很高,所以我自己找了手边的一些东西来测试,尽量保证背景对比度高。
如果识别单个物体,它的准确率还是很高的:

识别视频也是一样:

可以看到视频其实是逐帧识别的:

效果总结
这个模型在识别单个物品时准确率很高。上边在识别蔬菜时可能会识别成可回收物,这是正常现象,因为我找的蔬菜都太完美了,跟假的似的。如果有那种稍微烂一点的蔬菜就会被识别成厨余。
总体而言效果不错,我打算先用这个模型,同时再去训练一个更多轮的。
导出和格式转换
模型下载下来是一个.pt格式,根据参考文章转成.om。
转onnx
首先调用yolov5的export.py将.pt转换为.onnx:
# 这两个涉及路径的参数需要改:
parser.add_argument('--data', type=str, default=ROOT / 'data/UA-DETRAC.yaml', help='dataset.yaml path')
parser.add_argument('--weights', type=str, default=ROOT / 'best.pt', help='weights path')这里又有个坑,可能要手动装一个onnx。装的时候注意不能指定版本,否则不知道报什么错。装好之后要在参数里指定
--include onnx因为最新版yolov5默认的格式是.torchscript。
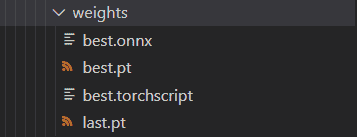
运行后可以在导出路径找到文件。
测试.onnx推理无误,这里的测试方式和上边一模一样:
python detect.py --weights runs/train/exp15/weights/best.onnx --source ../data/8.mp4但是可能需要手动装一个onnxruntime和onnxruntime-gpu。但我发现,即使装了也会发生解析错误无法用gpu推理,一个500多帧的视频推了好久。这个问题暂且搁置。
测试发现推理无误,进行下一步。
转om
这个过程我放在板子上完成。因为学校的服务器我没有root权限,不能给软件包授权。按要求下载python包后,从这个链接下载CANN。
以下是普通linux机器的转换方式(这种方式需要一个大内存的linux机器)。
添加执行权限:
cd ~/Downloads/
chmod +x Ascend-cann-toolkit_7.0.RC1_linux-x86_64.run安装
./Ascend-cann-toolkit_7.0.RC1_linux-x86_64.run --full配置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
export LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/latest/x86_64-linux/devlib/:$LD_LIBRARY_PATH安好之后可以开始转换模型。
atc --model=best.onnx --framework=5 --output=model --input_format=NCHW --soc_version=Ascend310B4如果用板子就简单,但也慢很多了:
先在用户目录下创建一个om_convert目录,之后把.onnx模型传进来,解除内存限制之后就可以直接开始转换:
atc --model=best.onnx --framework=5 --output=model --input_format=NCHW --soc_version=Ascend310B4
# 注意不该加的参数不要加,如果没有明确的输入shape就别加这个参数。其中--soc_version是昇腾处理器型号,jupyter自带的说明文档里的不一定准,可以用命令npu-smi info得到。这里别乱写。
因为昇腾设备一般自带CANN,所以命令一输进去应该就能看到ATC start working now的提示。但是整个过程会很漫长。
转换过程中可能会报一些错或警告,这个不用管·,最后能出模型就行。但是我在用这种方法转换时,无论如何尝试都有BrokenPipeError,无奈之下放弃尝试,还是用服务器去做转换。
但是经过多次尝试,仍然未能解决BrokenPipeError的报错。
2024年11月9日18:59:21
找到了一位强劲的外援帮我解决了这个问题,现在我已经获得.om格式的模型了。至于出现报错的原因还有待研究,先暂且放在这。

模型使用
获得.om模型后就可以开始做推理了。我先直接套samples中的推理代码来用。因为那里边的推理代码已经集成了摄像头的接口,如果能跑通的话后期要加摄像头就只是点点鼠标的事。
直接移植
如果直接把.om模型换掉,效果会不太好:

可以看出框得不够准确,而且即使我调高了置信度和边框阈值,它还是有很多框在上边乱闪。还有一个问题是它现在似乎只能识别其他垃圾。
使用原版推理
这其实是一个比较取巧的方法,既然我的目的只是用这块板子去实现智能系统,那我为什么非要调优一个om而不用现成的pt推理呢?将detect.py的参数修改为0,调用摄像头看看效果:

虽然没有静态视频那么好,但是其实也能接受。我打算这两天看看能不能借到一个摄像头,在有摄像头的情况下优化模型会方便很多。因为其实能看出来虽然都是视频识别,但是实时视频和静态视频的效果还是大相径庭。
到现在我已经把模型准备完毕了,后期就差加模块然后优化模型。优化的工作看时间来做吧。
2024年11月9日22:40:33
模块集成
摄像头
2024年11月10日14:37:29
今天拿到了一个usb摄像头,比较高级,长这样:


不知道速度效果啥的怎么样。
测试
在插摄像头的时候我发现,这上边只有两个usb口,我的鼠标键盘插上去就没地方插摄像头了。我尝试把扩展坞插在另一个type-c口上,但是不出我所料,这个口也是只供电不能传数据。我又花了一些时间研究怎么连上蓝牙键盘。只能说幸亏当时买的是三模的键盘。
命令调用
先查看设备节点,这个每次重启都要看,它会变。
apt install -y v4l-utils
v4l2-ctl --list-devices输入后,如果插了摄像头就能得到设备的节点号:

用命令拍张照,需要安装fswebcam
apt-get install -y fswebcam
fswebcam -d /dev/video1 --no-banner -r 1280x720 -S 5 ./image.jpg照片效果
我首先在台灯光线下拍了一张,结果黑糊糊一片啥也看不清:

之后我尝试用手机摄像头打光,效果稍好了一些:

把台灯挪近,营造一种摄影棚光的效果:


效果好了很多,但还是有种阴间滤镜。我怀疑是不够亮,于是照着室外拍了一张:

又过度曝光了。所以我觉得如果直接拍照,它只能在非直射的自然光或强光条件下使用。比如这张图中旁边的椅子就很清楚。
代码调用
在自带样例中改为摄像头输入,得到实时画面:

出乎意料地,视频效果还不错,帧数很高,我先前的担心都是多余的。我怀疑照片不行是因为没有给它足够的曝光时间。这个事有空再过来研究,我下一步是把这个模块集成进推理代码。
最简单的方法就是直接在detect.py里改,和上边win系统一模一样。
但是这么改不行,会报错说访问越界找不到摄像头:
[ WARN:[[email protected]](mailto:[email protected])] global cap_v4l.cpp:999 open VIDEOIO(V4L2:/dev/video0): can't open camera by index
[ERROR:[[email protected]](mailto:[email protected])] global obsensor_uvc_stream_channel.cpp:158 getStreamChannelGroup Camera index out of range这个问题搞树莓派遇到多回了,其实就是之前我在jupyter开的那个进程即使手动停止了也没被销毁,导致摄像头一直被占用着。只要拔掉再接上就好了。可以确实在板子上用摄像头做垃圾识别了,而且看效果识别准确率很高。但是由于用的是pt模型所以有点慢。视频很卡,这个是必须要优化的:
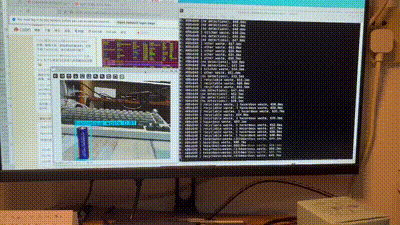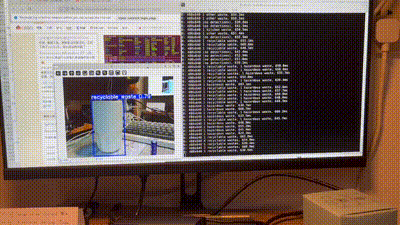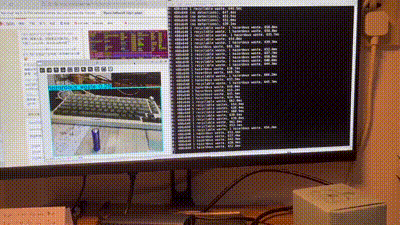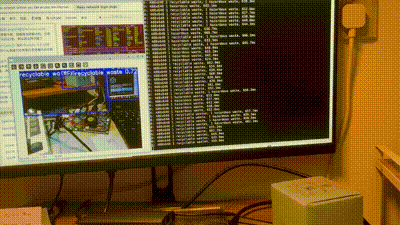
其实到这里,我的设计就已经完成了(那个语音模块有兴趣再加吧,那个东西就不能简单调接口了,得自己加东西,是个大工程)。我原定的就是用这一整个周末把这个课设搞完,现在也算是达成这个规划了。后续我的实验报告也会从这篇博文中整理出来。
优化工作是一个很磨人的过程,这几天慢慢想想办法找找资料再回来做。
2024年11月10日16:57:33
模型调优
改用yolo v11
由于1fps的帧率实在难以忍受,而我又不想花太多时间尝试新模型,所以我打算用更高代的yolo试试能不能提高点帧率。
这部分主要参考这篇文章。
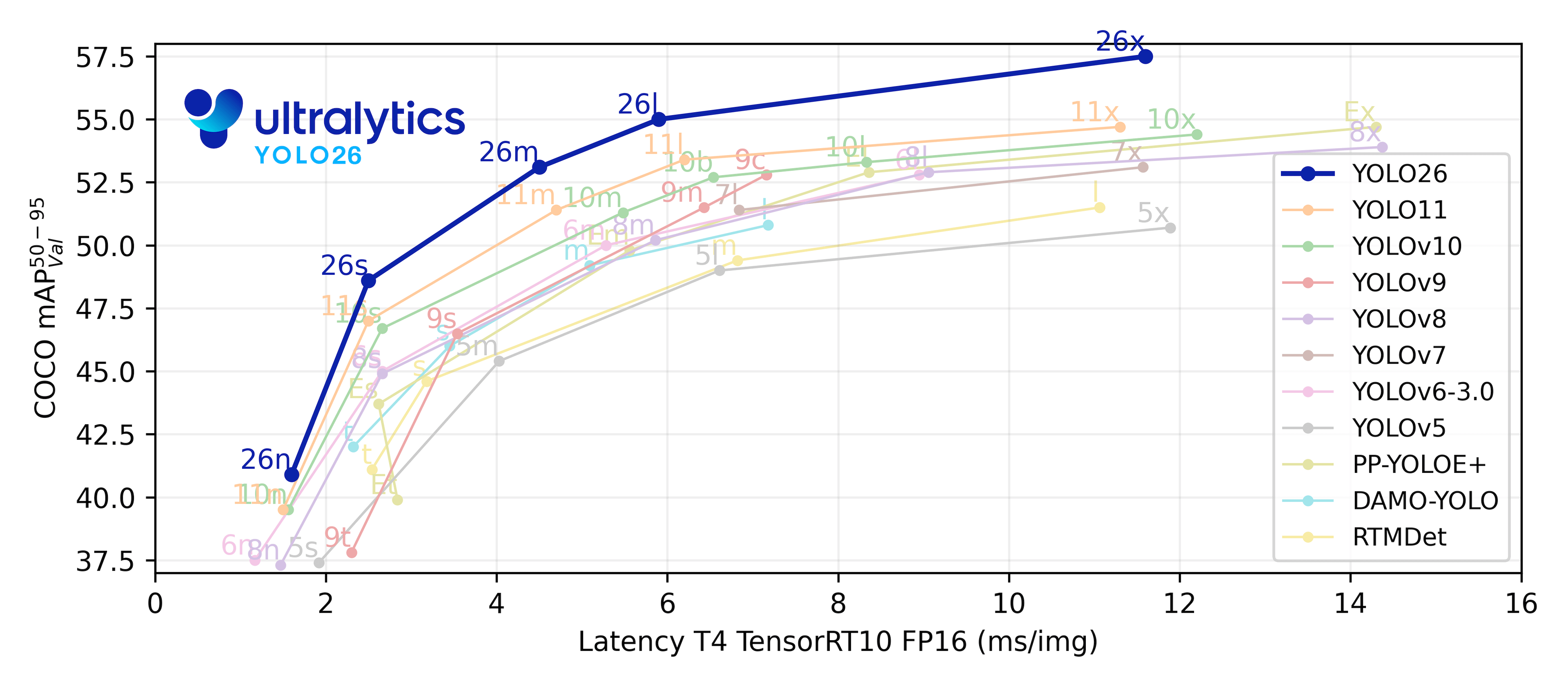
可以看出,11代的性能要好很多。这次由于追求帧率,所以我选择了最轻的模型:

这次的data.yaml写法是:
# dataset path
train: ./Imageset/images/train
val: ./Imageset/images/val
test: ./Imageset/images/test
# number of classes
nc: 4
# class names
names: ['recyclable waste', 'hazardous waste', 'kitchen waste', 'other waste']填好后可以直接开始训练,需要手动编写train.py文件:
from ultralytics.models import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
if __name__ == '__main__':
model = YOLO(model='ultralytics/cfg/models/11/yolo11.yaml')
# model.load('yolov8n.pt')
model.train(data='./data.yaml', epochs=200, batch=64, device='0,1', imgsz=640, workers=2, cache=False,
amp=True, mosaic=False, project='runs/train', name='exp')这次配环境时只需要安装ultralytics一个包即可自动安装所有Requirements,非常方便。我一开始还找了半天Requirements.txt在哪,体会到了读文档的重要性。
训练时报错说找不到数据集路径。这里有一个坑,它的默认根目录是:
Note dataset download directory is '/share/home/lingwang/zyp/yolov5/datasets'. You can update this in ...需要手动改成当前目录。改好后可以开始训练:

结束后权重默认保存在runs/train下,同时可以在reaults找到可视化的训练过程:



相同地,预测代码也要自己写:
from ultralytics.models import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
if __name__ == '__main__':
model = YOLO(model='./run/train/exp/weights/best.pt')
model.val(data='./datasets/data.yaml', split='val', batch=1, device='0', project='run/val', name='exp',
half=False,)同时可以模块化地做这件事:
from ultralytics.models import YOLO
def no_show():
model = YOLO(model='runs/train/exp3/weights/best.pt')
model.predict(source='1.jpg', device='0', imgsz=640, project='runs/detect/', name='exp')
def visible_predict():
model = YOLO(model='runs/train/exp3/weights/best.pt')
results = model('1.jpg')
for result in results:
boxes = result.boxes
result.show()
result.save(filename='2.jpg')
if __name__ == '__main__':
visible_predict()如果只预测类型而不画框,推理会快很多。所以在真正做推理时可以不可视化而只返回类型。
如果要导出为onnx格式,只需:
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load an official model
# model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")注意这里需要一个额外的onnx包。这次转换完之后只有11m,比v5的权重文件整整小了四倍。
ok,到这一步就算炼出丹药了。接下来接摄像头测试。把整个系统迁移到板子上,其实只需要装个环境,推理代码和权重文件现在都已经获得。
遗憾的是,在改用yolo11后帧率仍然不佳,只有2fps,而且精度等也有下降。
在排查问题的过程中我发现,根源还是在于格式,似乎必须是om私有格式的模型才能收获一个看得过去的结果,比如我跑一个赛车识别的om模型:

反观我的垃圾分类:
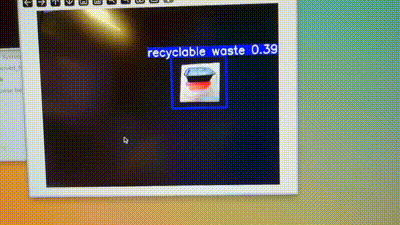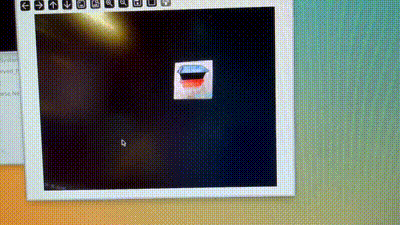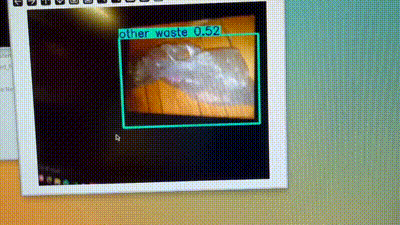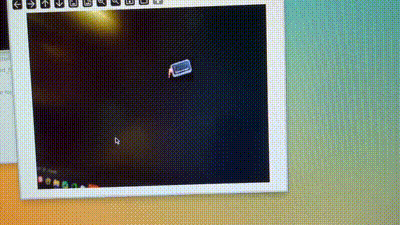
准确率确实很高,但是帧率感人,还是要想办法把它无损地转化为om格式。
2024年11月28日00:20:58
到现在我关于换模型的尝试宣告失败。
后续重点
我发现在不转换为私有格式的前提下,对模型本身做任何修改都是细枝末节,能优化的余地可以说聊胜于无。这整个作业项目最难的地方就在于如何把模型从onnx转换为私有格式om。这个只要能成功就不需要优化了。但是这个事很难,以后问问别人再看看咋做。
总结
这次作业严格来说并没做完,甚至不能算做出了什么成果,因为我没有用NPU推理成功。但是幸亏老师看在我愿意做出实物的份上打了个比较好的成绩,这门课我最终拿到了总评94分,位列教学班第一名:

